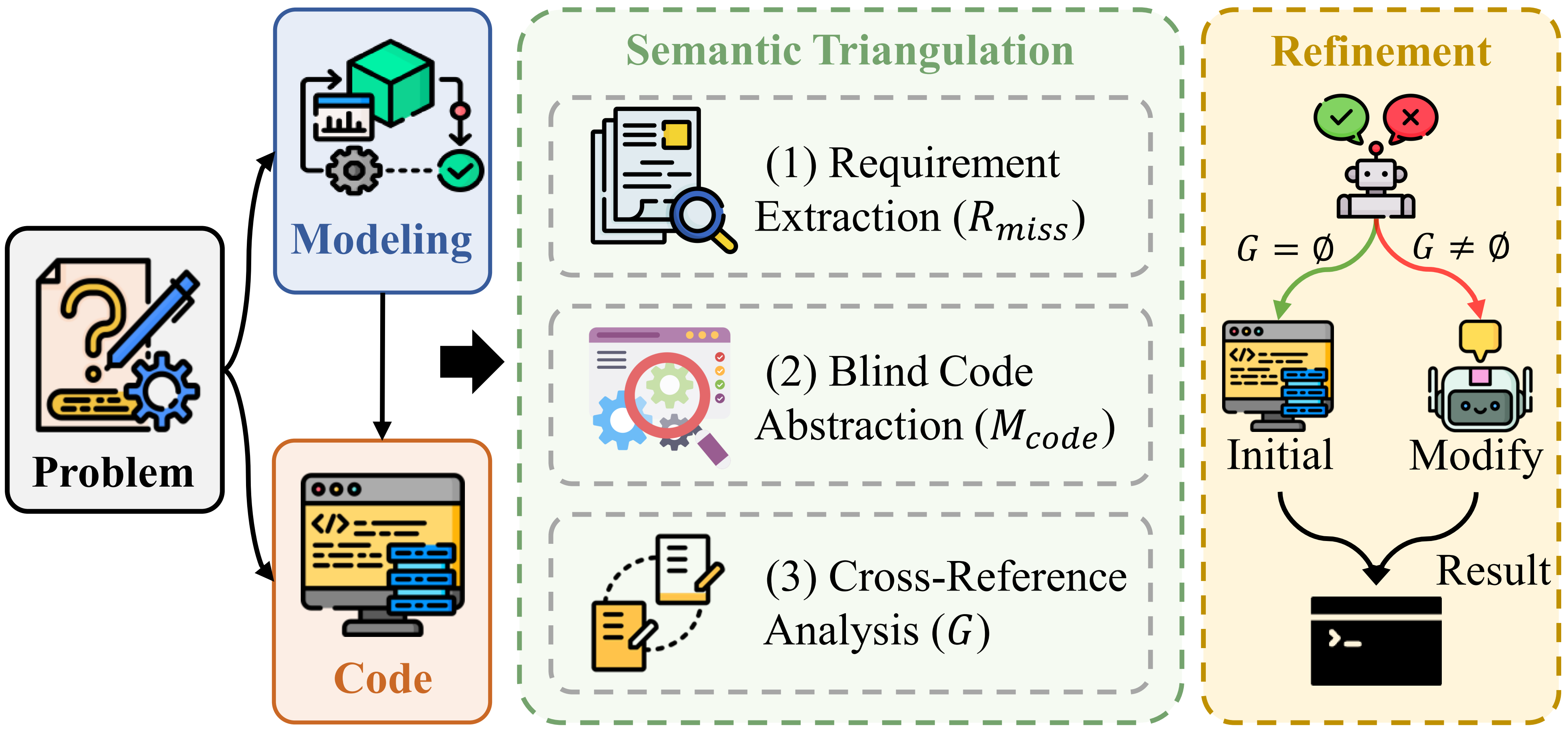
Benchmark Details
Key Components
- Dataset Size: 1,000 high-quality, curated optimization problems.
- Six Domains: Mathematical Programming (MP), Combinatorial Optimization (CO), Stochastic Optimization (SO), Dynamic Optimization (DO), Optimal Control (OC), Game Optimization (GO).
- Three Difficulty Levels: Easy (300), Medium (400), Hard (300).
- Cross-Paradigm Versatility: Requires models to autonomously identify the paradigm and write executable code using various solvers (gurobi, scipy, cvxpy, pulp, etc.).

| Benchmark | Size | Table | Graph | Answer Form | MP | CO | SO | DO | OC | GO |
|---|---|---|---|---|---|---|---|---|---|---|
| ComplexOR | 37 | ❌ | ❌ | Scalar | ✅ | ✅ | ❌ | ❌ | ❌ | ❌ |
| NLP4LP | 269 | ❌ | ❌ | Scalar | ✅ | ✅ | ❌ | ❌ | ❌ | ❌ |
| MAMO | 863 | ✅ | ✅ | Scalar | ✅ | ✅ | ❌ | ❌ | ❌ | ❌ |
| OptiBench | 605 | ✅ | ❌ | Scalar | ✅ | ✅ | ❌ | ❌ | ❌ | ❌ |
| OptiVerse (Ours) | 1000 | ✅ | ✅ | Vector | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |